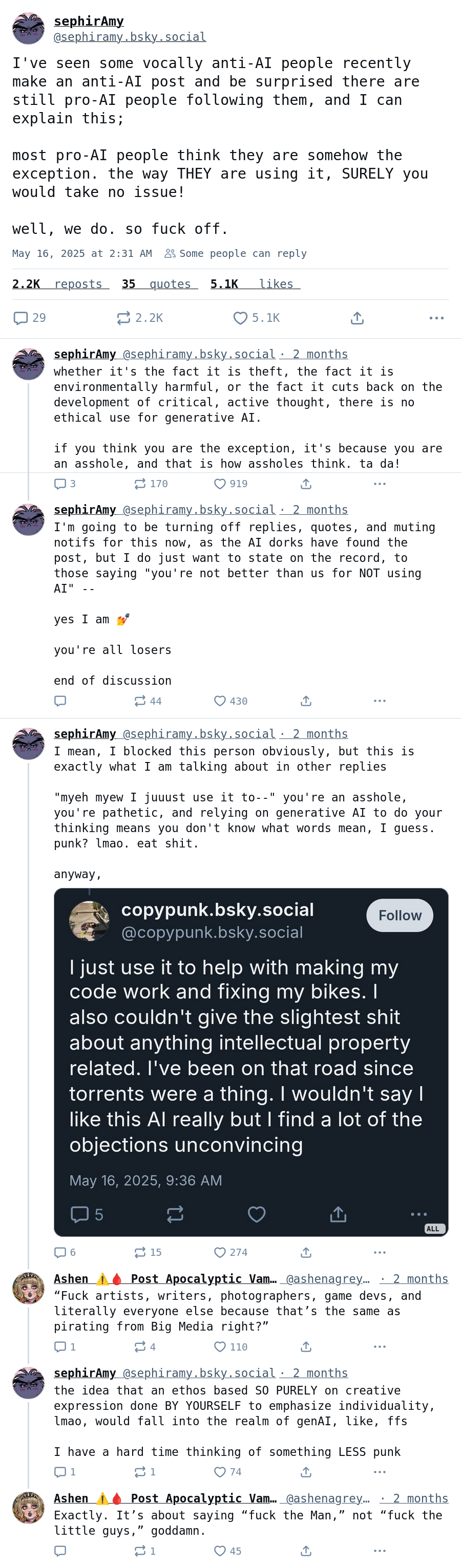
Copyright law is more or less always formulated as limits on the rights to redistribute content, not how it is used. Hence, it isn’t a particularly strange position to take that one should be allowed to do whatever one wants with gen AI in the private confines of ones home, and it is only at the moment you start to redistribute content we have to start asking the difficult questions: what is, and what is not, a derivative work of the training data? What ethical limitations, if any, should apply when we use an algorithm to effortlessly copy “a style” that another human has spent lots of effort to develop?
That makes sense wrt redistribution, but the original comment limited itself to the ethical problem and not the legal problem. I just don’t see how it makes sense in that context because it’s entirely unclear who owns the work, that’s the nature of the technology.
If I train a model on the work of 1000 artists each of them contributes some fractional amount to each weight. When that model generates an image, it’s combining a pseudorandom human token input with the weights and some random seed info.
If I provide a prompt of my own making, am I stealing 1/1000 of the content from each artist? Is the result 1/3 mine from my token input? Is the result 100% the property of whoever trained the model? Do we need to trace the traversal of the weights and sum the ownership of each artist based on their contribution to that weight? Is it nobody’s due to the sheer number of random steps that convert the input intent to the final result?


{kind=link}
Copyright law is more or less always formulated as limits on the rights to redistribute content, not how it is used. Hence, it isn’t a particularly strange position to take that one should be allowed to do whatever one wants with gen AI in the private confines of ones home, and it is only at the moment you start to redistribute content we have to start asking the difficult questions: what is, and what is not, a derivative work of the training data? What ethical limitations, if any, should apply when we use an algorithm to effortlessly copy “a style” that another human has spent lots of effort to develop?
That makes sense wrt redistribution, but the original comment limited itself to the ethical problem and not the legal problem. I just don’t see how it makes sense in that context because it’s entirely unclear who owns the work, that’s the nature of the technology.
If I train a model on the work of 1000 artists each of them contributes some fractional amount to each weight. When that model generates an image, it’s combining a pseudorandom human token input with the weights and some random seed info.
If I provide a prompt of my own making, am I stealing 1/1000 of the content from each artist? Is the result 1/3 mine from my token input? Is the result 100% the property of whoever trained the model? Do we need to trace the traversal of the weights and sum the ownership of each artist based on their contribution to that weight? Is it nobody’s due to the sheer number of random steps that convert the input intent to the final result?
Robots can not have style, so infinite ethical limitations.