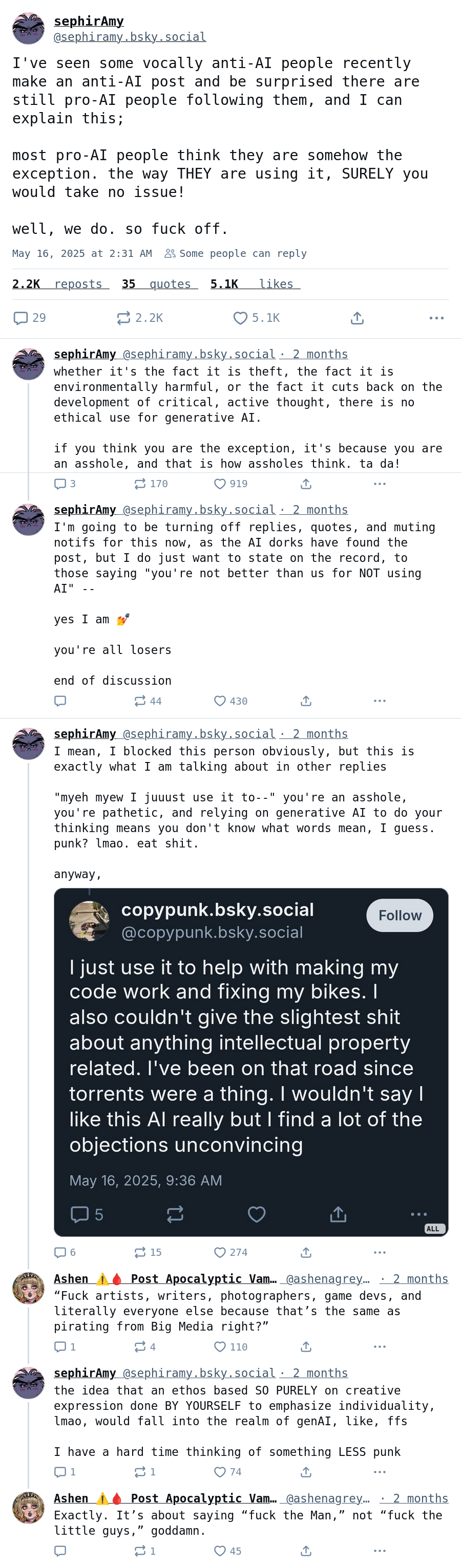
I won’t call your point a strawman, but you’re ignoring the actual parts of LLMs that have high resource costs in order to push a narrative that doesn’t reflect the full picture. These discussions need to include the initial costs to gather the dataset and most importantly for training the model.
Sure, post-training energy costs aren’t worth worrying about, but I don’t think people who are aware of how LLMs work were worried about that part.
It’s also ignoring the absurd fucking AI datacenters that are being built with more methane turbines than they were approved for, and without any of the legally required pollution capture technology on the stacks. At least one of these datacenters is already measurably causing illness in the surrounding area.
These aren’t abstract environmental damages by energy use that could potentially come from green power sources, these aren’t “fraction of a toast” energy costs only caused by people running queries either.
Nope, I’m not ignoring them, but the post is specifically about exceptions. The OOP claims there are no exceptions and there is no ethical generative AI, which is false. Your comment only applies to the majority of massive LLMs hosted by massive corporations.
The CommonCorpus dataset is less than 8TB, so fits on a single hard drive, not a data center, and contains 2 trillion tokens, which is a relatively similar amount of tokens that small local LLMs are typically trained with (OLMo 2 7B and 13B were trained on 5 trilion tokens).
These local LLMs don’t have high electricity use or environmental impact to train, and don’t require a massive data center for training. The training cost in energy is high, but nothing like GPT4, and is only a one time cost anyway.
So, the OOP is wrong, there is ethical generative AI, trained only on data available in the public domain, and without a high environmental impact.


{kind=link}
I won’t call your point a strawman, but you’re ignoring the actual parts of LLMs that have high resource costs in order to push a narrative that doesn’t reflect the full picture. These discussions need to include the initial costs to gather the dataset and most importantly for training the model.
Sure, post-training energy costs aren’t worth worrying about, but I don’t think people who are aware of how LLMs work were worried about that part.
It’s also ignoring the absurd fucking AI datacenters that are being built with more methane turbines than they were approved for, and without any of the legally required pollution capture technology on the stacks. At least one of these datacenters is already measurably causing illness in the surrounding area.
These aren’t abstract environmental damages by energy use that could potentially come from green power sources, these aren’t “fraction of a toast” energy costs only caused by people running queries either.
Nope, I’m not ignoring them, but the post is specifically about exceptions. The OOP claims there are no exceptions and there is no ethical generative AI, which is false. Your comment only applies to the majority of massive LLMs hosted by massive corporations.
The CommonCorpus dataset is less than 8TB, so fits on a single hard drive, not a data center, and contains 2 trillion tokens, which is a relatively similar amount of tokens that small local LLMs are typically trained with (OLMo 2 7B and 13B were trained on 5 trilion tokens).
These local LLMs don’t have high electricity use or environmental impact to train, and don’t require a massive data center for training. The training cost in energy is high, but nothing like GPT4, and is only a one time cost anyway.
So, the OOP is wrong, there is ethical generative AI, trained only on data available in the public domain, and without a high environmental impact.