- 2 Posts
- 21 Comments

 7·1 day ago
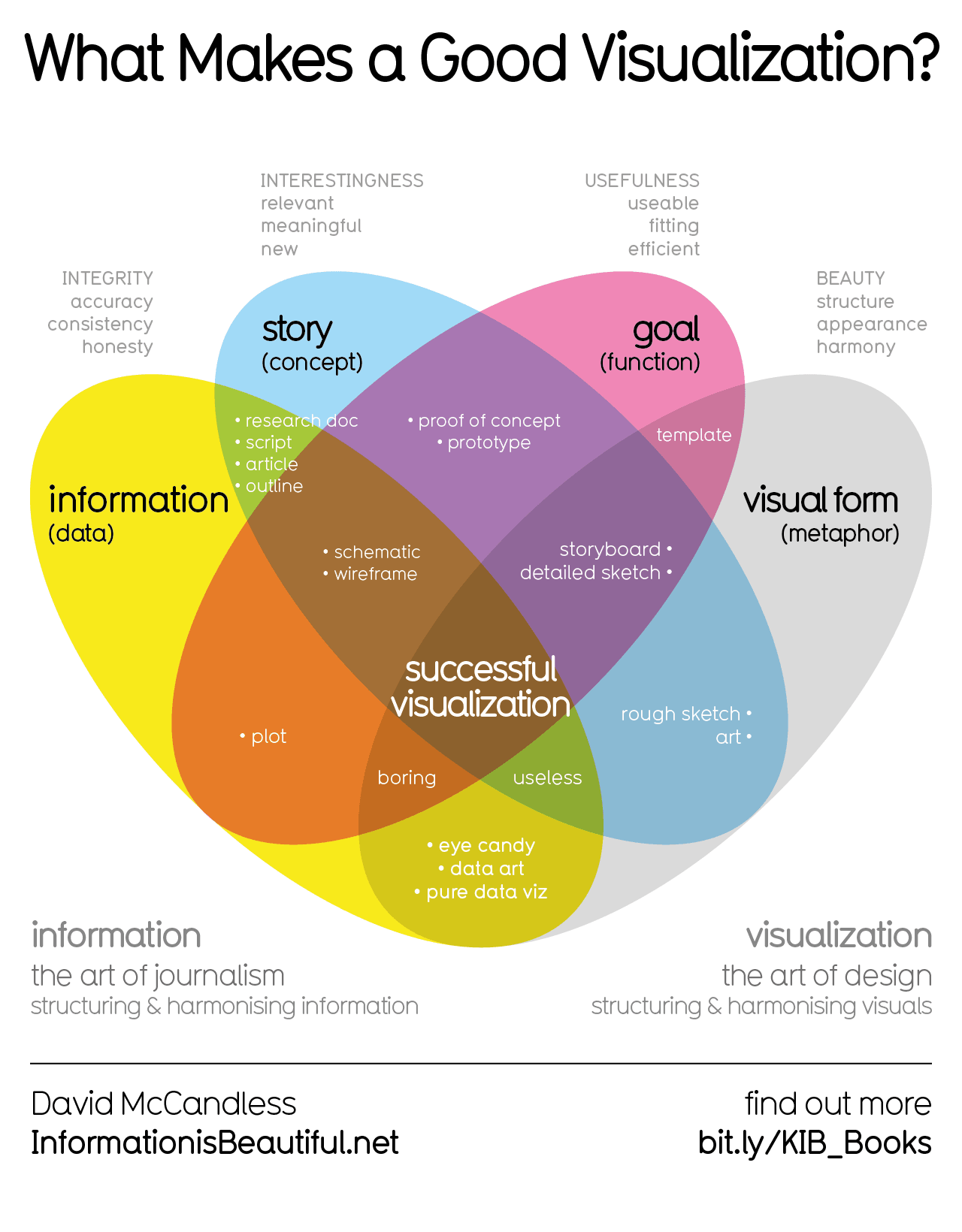
7·1 day agoThis is extremely interesting. How many magazines and newspapers are digitized in the way you can analyze them like that? This is a simple word-based analyze, also those texts can be enriched with metadata, e.g. mentions of people can be marked with their identifiers in Wikidata.
I was going to remind of how good “filtered keywords” function is, but suddenly it struck me I shouldn’t have seen this post in the first place. Apparently, I saw it because my block list had a flaw.
 13·4 days ago
13·4 days agoI thought this was a normal coding. Then how do you call those who heavily rely on google and SO?
On fediverse projects - yes. In mainstream social networks - no.
A day will come when I get to know what vibecoding is. Or maybe this word will die out sooner. You never know.
Does this picture mean “consume a lot of posts and news on these topics and participate in comments section”?
It’s solving device addiction with another device. Sure it will be very interesting to investigate phone models to pick from. Indeed we are good at tricking ourselves. Creating “windows” with no phone at all works better for me.
It’s imgur, pretty unpleasant website.

I wonder, when you chose those instances, how far from the top they have been comparing by users count.
We live in society
With this amount of money, they could’ve allowed to download any JDK from their website without creating an account.
@moseschrute@lemmy.world You were talking about something like that
 3·8 days ago
3·8 days agoThis is awesome. I believe difference from client-side filtering is that filters will work everywhere you login with your account. Do you happen to know estimated 1.0 release date?
Probably there’s too small userbase for continuous subscribable block lists. I think I’ve seen some people sharing their blocklists on anonymous imageboards. When you can import/export block lists as plain text, probably it is enough.
Consider checking syntax where it’s already implemented and adding this import/export functionality.
A step forward could’ve been adding some logic: e.g. some keywords are filters for posts, some for comments, some for community/instance name. Maybe complex filtering can make federated “global” feed much more satisfying.
Not quite. I’d rather use Lemmy in web browser on desktop. Right now, I’m looking through these app lists: https://www.lemmyapps.com/ https://join-lemmy.org/apps https://lemmy.world/post/2609614 .
Photon, Alexandrite, mlmym are not supporting filters, but blorpblorp supports.
I see it exists on Voyager for iOS
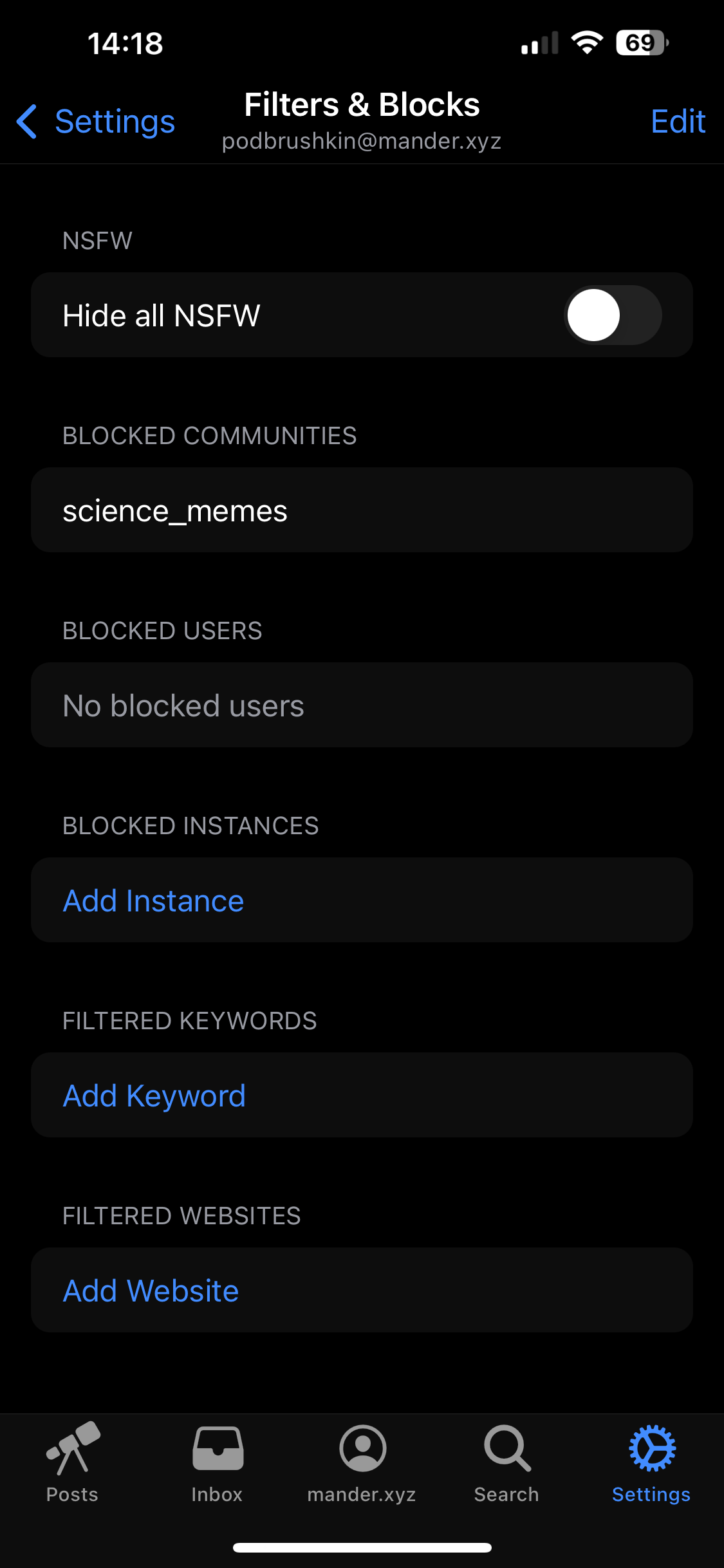
Thank you, but I don’t have an Android.
Make sure to check out LifeMap external url where it is available. Chosen taxon will be found in another tree-exploration tool, which is more fine-grained and is more suitable for exploring small branches and closest neighbors of chosen taxon in terms of hierarchy.
Some software solutions exist, e.g. War and Peace by Tolstoy can be downloaded with metadata, ids are assigned to all characters and when one character tells something to another, this is highlighted as “x speaks to y”, and you can run a community detection algorithms on this data. I think in the paper they’ve been mentioning some proprietary software. I suspect detecting who speaks to whom is even harder.
Also, some form of crowd sourcing probably should be possible. At least collecting scans is possible on wikisource and wikimedia commons.
Probably AI language models should be pretty good in distinguishing between linguistic ambiguities.
I dream for a time when such reports as in OP post will be a matter of work for an hour or two — because data will be already collected and clean.