(Multimodal) GPT ≠ “pure” LLM. GPT-4o uses an LLM for the language parts, as well as having voice processing and generation built-in, but it uses a technically distinct (though well-integrated) model called “GPT Image 1” for generating images.
You can’t really train or treat image generation with the same approach as natural language, given it isn’t natural language. A binary string doesn’t adhere to the same patterns as human speech.
Text prompts are first tokenized into word embeddings, while image inputs—if provided—are converted into patch embeddings […] These embeddings are then concatenated and processed through shared self‑attention layers.
I haven’t found any other sources to back that up, because most platforms seem more concerned with how to access it than how it works under the hood.
You’re right that image generation models are not LLMs, but they actually are pretty closely related. You may already know how they work, but for those that don’t, it’s kind of interesting. It uses a similar pipeline for vectorization of input, but takes a different approach for output.

{kind=link}
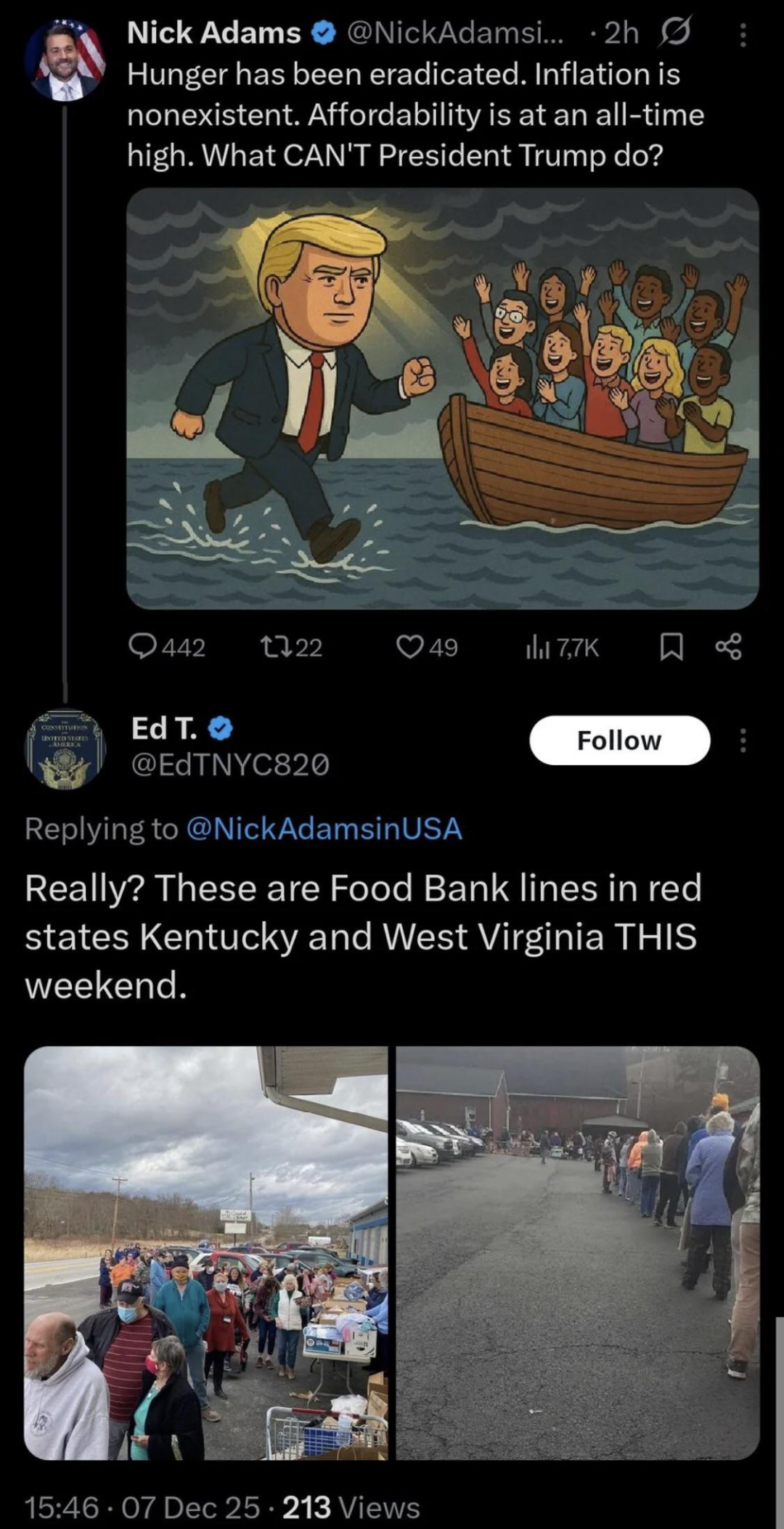
LLM slop factories are overtly racist because they’re trained on shit lifted straight off the internet.
That’s image generation, not LLM (language/text generation), but the point stands
Hate to bring it to you, but today’s image generation comes through LLMs
(Multimodal) GPT ≠ “pure” LLM. GPT-4o uses an LLM for the language parts, as well as having voice processing and generation built-in, but it uses a technically distinct (though well-integrated) model called “GPT Image 1” for generating images.
You can’t really train or treat image generation with the same approach as natural language, given it isn’t natural language. A binary string doesn’t adhere to the same patterns as human speech.
Just curious, does the LLM generate a text prompt for the image model, or is there a deeper integration at the embedding level/something else?
According to CometAPI:
I haven’t found any other sources to back that up, because most platforms seem more concerned with how to access it than how it works under the hood.
You’re right that image generation models are not LLMs, but they actually are pretty closely related. You may already know how they work, but for those that don’t, it’s kind of interesting. It uses a similar pipeline for vectorization of input, but takes a different approach for output.